Wheelhouse Pricing Engine: Complete Overview
April 19, 2021 | Andreas Buschermohle

Intro
Wheelhouse Pro is our most robust and professional pricing platform to date.
It was designed for ambitious operators with growing portfolios, prioritizing deep data insights and better portfolio tools, all while delivering even stronger revenue performance.
Additionally, Wheelhouse Pro will further our own goals of providing increased transparency to our customers and community.
We believe transparency is the key to empowering our users to make informed business decisions, and it is high time our space moved from ‘making recommendations’ to ‘providing explanations’.
Therefore, in the following pages, we are going to detail exactly how our dynamic pricing engine works — how it leverages data, unique statistical approaches, and (yep!) machine learning to calculate accurate prices for your unique properties.
Over the course of this write-up, we will leverage visuals, text and occasionally equations (😳) to articulate the models, quality checks, filters and data underpinning Wheelhouse’s revenue management platform, that today increases revenue by an average of 22%, per unit.
At worst, should our write-up prove to be a bit too dry or detailed, we hope detailing the model will illustrate our deep commitment to your success, and to the transparency we believe our space so desperately deserves.
At best, we hope detailing our model will give you new insights that you can leverage to drive your business’s success.
Pricing Engine: Components
- The Base Price Model
- The Predictive Demand Model
- The Reactive Demand Model
- Location Impact
- Occupancy Impact
- Impact of Prior Bookings
- Booking Curves
- Gamma Warping
- Price Response Function
- Model Blending
- Calendar Control
- Vacancy Gaps
- Last Minute Discounting
Additionally, in this write-up, we have decided to break out two important models to explore them in greater detail:
- Competitive Set Model
- Dynamic Pacing Model
Now, let us step through these models, starting with our pricing engine’s foundation, the Base Price Model.
Part 1: Base Price Model
How our model determines an accurate price for your unit at ‘normal’ demand
As stated above, the Base Price Model is the foundation of each unit’s unique pricing recommendation. The goal of the Base Price Model is to discern an accurate median nightly price for each unit by analyzing the attributes of the property.
For example, we all know that a pool, a porch, parking and other attributes can impact the desirability of a given property.
And, while the value of these individuals attributes varies greatly over the course of a year (i.e. your pool is ‘worth’ more on July 4th than on January 4th), the Base Price Model is designed to determine the value of your unit for a day with average local demand.
To do this, the Base Price model analyzes:
- Attributes (e.g. bedrooms, bathrooms, parking, sleeps, unit type, etc.)
- Fees (e.g. cleaning fee, security deposit, extra guest fee, etc.)
- Location
- Booking performance (i.e. every booking, for your and nearby units)
And a range of additional factors.
To train our Base Price Model, we use a supervised machine learning model that incorporates all active units in each market, leveraging their unit details and the median nightly price over the last year. By using the median, we can reduce the signal from events or accidental outliers in the data to make sure we primarily capture pricing for ‘normal’ days.
Our model leverages gradient boosting to produce an ensemble of decision trees, which map a unit’s features to the median price. For our customers, this approach enables us to balance model complexity with interpretability — or the ability to show you how your unit’s attributes impact your Base Price recommendation.
Let us explore an example to learn more.
Detailed in the chart below are the five largest drivers of the Base Price in the San Francisco market (Note: real data is used throughout all examples in this write-up)

We can also see that the unit type (e.g. private room, entire apartment, full house, etc.) plays a significant role in determining an accurate Base Price in San Francisco, as do the extra fees (both cleaning and guest fees) associated with each stay.
While this graph offered us a high-level understanding of the value of the attributes, let us dive in more deeply to the most impactful attribute — bedrooms. To do this, we will examine a series of sample units that have:
- a variable number of bedrooms (From 0BR, i.e. a studio, to 4BR)
- But, all have one bathroom and ‘sleep’ four guests

However, what you might have realized is that this example is constrained in the sense that all these hypothetical units are restricted to having 1BA and ‘sleeping’ 4. In reality, most 4BR units will both have more than one bathroom, and sleep more than 4 people.
Therefore, examining this constrained example illustrates a core aspect of our Base Price Model though, as it is intended to illustrate that an accurate Base Price must consider the value of attributes both individually and collectively.
Location Impact
The location of a unit can dramatically impact the perceived and actual value of that unit.
To determine this impact, our model leverages our Base Price Model, by applying spatial kriging to our Base Price Model’s residuals. In our model, the ‘residuals’ refer to percentage differences between our predicted and the actual median prices for each unit, as illustrated below.
In the visual below, we can see that our model has identified a set of clustered units (yellow dots) that mostly have a median nightly price above our ‘predicted’ median price (‘predicted’ based on the unit’s attributes).

Occupancy Impact:
One challenge in the short-term rental space is that many units are unintentionally (or intentionally!) ‘incorrectly’ priced.
Therefore, it is critical to leverage occupancy data (occupancy achieved over the prior year) to better understand how much our model should ‘weigh’ each unit’s pricing strategy. In combination with prices, the occupancy rate achieved by a unit can help us better understand whether a unit is overpriced or underpriced, relative to the market. Hence, we provide the occupancy as an input to our Base Price Model during training to tease out this relationship.
Of interest, despite units in the STR space being very unique, among the millions of units we have analyzed, the aggregate booking patterns reveal that the STR market is actually very efficient.
To explore this more, let us examine the chart below, which illustrates the relationship between a unit’s Base Price, and occupancy rates. As you can see, as the achieved occupancy increases, the Base Price associated with these units decreases.

Accuracy Evaluation
For our model to be effective, we need to avoid overfitting and ensure that the out-of-sample error is minimized. For this, our model uses cross validation during the training process.
In our example of San Francisco, we train the Base Price Model using data from more than 5,000 units through the steps laid out above. A majority of units will have prices close to the right Base Price, while some will be priced too high or too low.
The below image is a histogram chart of a unit’s recommended prices relative to their current median price.
As you can see, most recommendations are pretty similar to the median price, i.e. have a value close to 1.0 (or 100%). However, a few units are currently underpriced and would get a recommendation as high as twice their current price, i.e. 2.0, while others are currently overpriced and would get a recommendation as low as 30% of their current price, i.e. 0.3.
The histogram shows that our Base Price Model
- Reflects the market accurately, i.e. most units are close to 1.0
- Is not biased, i.e. there is a similar amount of outliers to both sidesI
- Does not overfit to the training data, i.e. the spread of the distribution is not too narrow.

The final output of this model is our “Attributes-Only” Base Price Model.
Now, let’s read about how bookings impact & modifies our Base Price Recommendation.
Part 2: Analyzing Bookings
Booking Curves
Unlike hotels, in the short-term rental space, the vast majority of STR supply is comprised of individual units. These individual units can only be either 100% booked or 100% vacant for a given night. Said differently, for any given night, your unit will either earn some or no money! Adding another degree of complexity to pricing the STR space is that once an individual unit is booked, you can never sell that night again.
Therefore, our model needs to be exceptional at maximizing the expected revenue from your unit, based on a series of ‘binary’ outcomes.
When we started Wheelhouse 6 years ago, our team spent 12+ months testing different statistical approaches to determine which approach could best maximize revenue outcomes, over time.
The Kaplan-Meier estimator inherently handles ‘right censoring’. This is because for any unbooked future date, we do not yet know when, or even if, that night will be booked or otherwise taken off the market. Therefore, it is crucial to be able to include this data in order to fully understand supply and demand in a dynamically changing market.
The output of Survival Analysis is a survival curve S(t). It reflects the probability of a unit not being booked by time t ≤ 0 which counts the number of days before the stay date. For Wheelhouse, we can think of this survival curve as the inverse of a booking curve.
Note: Our survival curve counts the number of stay dates before the stay date, hence why the output is negative. For example, S(-30) = 0.7 means that on average 70% of the units survived (or, are still available) 30 days before the stay date. Consequently, the complement of the survival curve 1-S(t) represents the booking curve and its final value, 1- S(t=0), is the occupancy.

This is where our modeling approach becomes particularly powerful, as it enables us to create and compare booking curves for:
The next challenge is to translate the differences between two booking curves into a more fine-grained understanding of how these booking patterns will impact expected demand.
To create these projections, our team developed a technique we call Gamma Warping.
Gamma Warping
For example, let us compare the booking curve Sₐ(t) in San Francisco for August in relation to the annual booking curve S₀(t) in San Francisco.
For this, we find γ (gamma) such that S₀(0) = f(Sₐ(0), γ). The warping function f is constructed such that it ensures that all adjusted survival curves stay within [0,1] and are monotonously decreasing, and vice versa the booking curves are monotonously increasing.

The impact of gamma on the booking probability is non-linear, and thus depends on the baseline booking probability. To visualize the non-linear impact of these estimates on different baseline booking probabilities p₀, the following graph shows the booking probability resulting from an adjustment by γ=0.7.

The second example below also illustrates how an initial baseline probability of booking (40%, represented by the dashed line) is transformed by different gamma values.

Our model does not simply assume, “Since demand is up 10%, booking probabilities increase 10%, as well”. Instead, on a market by market basis, or for any subset of units, we can create demand curves that help us understand “when demand increases by X% in your market, your unit’s expected booking probability increases by Y%”.
While complicated, it is a very powerful means to generically estimate demand in a dynamic market under a variety of circumstances.
Price Response Function
For example, once we have determined that August is likely to have higher demand, we need to determine how much to increase prices, without dramatically lowering your probability of booking.
To develop a price response function for a market, our model looks at each unit and each stay date offered in the market, to calculate its relative price difference δ to our base price model.
We then ‘bucket’ the observations with similar price differences and apply our booking curve analysis to determine (via Gamma Warping) whether this bucket books more (γ > 0) or less (γ < 0) than the market average.
This analysis tells us how much a change in price impacts the booking probability which in term reflects the sensitivity of guests to different prices.
Using these estimates, we fit a smooth price response function:
γ = fᵣ(δ) = a + b ⋅ (δ − d)² ⋅ (δ > d)
to the data, which allows us to generalize the observed market behavior.
And, no surprise, if prices are below our base price recommendation, we can see that the booking probability increases, at least initially. Importantly though, at a certain point, lowering your prices no longer increases your likelihood to book.

In the following graph, you can again see that our price multiplier is not simply linear. In fact, it changes quite dynamically for projected occupancies above or below the baseline (in this example the baseline is still 40% — represented by the dashed line).

However, if the expected demand/occupancy is above the market baseline (i.e. anything more than 40%) our price recommendations would initially increase in a roughly linear fashion, before increasing exponentially during periods of ‘extreme demand’, to better capture market compression. Alternatively, you can see that during periods of low demand, our model will lower prices… but only slightly, and not past a certain point.
Now, with a deep understanding of how our recommendation engine analyzes individual units, their booking probabilities, and the elasticity of their prices, let us dive into how our model begins to understand and predict demand drivers for units, for a particular stay date.
Part 3: Predictive Demand Model
Now, let’s dive more into how we isolate drivers of local demand, and how we leverage those signals to create far-future price recommendations before booking patterns emerge (e.g. how should we price a unit 365 days from now, when only <1% of a market has booked?).
The first local demand model we employ is our ‘predictive’ model, which is intended to predict accurate prices before a market begins to book. While this model has a number of goals, its most important job is to ensure that we do not underprice units for far future stay dates.
This model is particularly important for the role it plays in pricing local events and holidays that start booking many months (or years!) ahead of a stay date, and offer the best times to capture revenue.
For our Predictive Demand Model, we analyze prices in markets, including future and historical pricing data from hotels and short-term rentals. These pricing signals contain local and historical insights that we can leverage to better ensure the far-future is accurately priced.
Additionally, to aid interpretability and effectiveness, our model can parse these pricing signals, to determine the ‘why’ behind future price increases, so we can better understand factors, including:
- Seasonality
- Day of Week
- Local Events
Determining Seasonality
Let us examine a chart that shows the average prices in San Francisco by day of year. In this chart, the dots represent the average price by day of the year. The line shows the output of our custom-designed low-pass filter that extracts the seasonality curve.
Via this method, it is clear that the high season in San Francisco is from July through October, while the rest of the year is relatively flat, in terms of seasonal demand.

Day of Week
To better understand this, let us examine a ‘weekend effect’ as shown in the following bar chart of ‘day of the week’ pricing for San Francisco and Austin. To better compare the two markets, we show the daily prices relative to the lowest price and how much more other days increase above that minimum.
As you can see, San Francisco’s isolated day of week pricing is mostly flat with a very modest weekend increase of 3%. However, Austin clearly shows regular high demand for weekends, with most units increasing prices more than 50% on an average weekend.
By knowing this pattern for each market, we can again more accurately interpret future pricing patterns, and accurately name these factors for our customers.

Local Events
While similar to our other two demand ‘filters’, this model additionally considers the location of each event when understanding how particular price signals should be translated to the broader market.
Unsurprisingly, most events only impact pricing for units proximal to the event. However, in most markets there are multiple annual events (e.g. a huge conference, event, or holiday) that are so large they drive price changes across an entire market. Due to this, our model needs to be able to both (a) identify hyper-localized pricing signals and (b) translate those signals into an estimate of the scale and breadth of each event.
We achieve this by analyzing local pricing signals, removing the Seasonality and Day of Week impact, before extracting ‘short’ price increases. These results are achieved via a custom designed high-pass filter. The result of this filter is a highly readable chart that allows both our team (and you!) to examine any market for event-driven demand.
As an example, let us examine what our model determined to be the ‘event impact’ for two different areas in San Francisco, Union Square (near downtown) and Golden Gate Park (4 miles from downtown, a popular concert area). (Note that these are projections only from our Predictive Demand Model, as of January 2020. More on this soon!)

However, in the second chart (below), we examine units near Golden Gate Park, 4 miles from downtown. In this chart, we can clearly see that the biggest events were projected to be the two music festivals — Outside Lands and Hardly Strictly Bluegrass. These events do not impact the downtown area. And, only Dreamforce, the largest of conferences, can be definitively tied to a specific price spike in the Golden Gate Park area.

Part 4: Reactive Demand Model
In the accommodations space, as stay dates approach, we are able to observe more bookings, and gain a more concrete understanding of demand. (While much of the accommodations space still leverages historical data to inform all pricing, we leverage actual bookings.)
Similar to our Predictive Demand Model, our Reactive Demand Model attempts to determine both how much and why demand is shifting. On a daily basis, our model re-analyzes your market, leveraging our prior referenced Booking Curves and Gamma Warping to re-forecast these three main demand drivers — seasonality, day of the week, and local events.
For a very visual example of this, let us look at our reactive demand model for downtown San Francisco, as calculated on January 1, 2020 (purple line) and March 15th, 2020 (yellow line).
As you can see, as of January 1st (purple line), our reactive demand model was projecting large demand spikes for many events in San Francisco, including Dreamforce, a huge annual event in October, in San Francisco.
However, by March 15th, you can see that event demand for Q2 (April — June) has essentially completely evaporated. Therefore the prior forecast price increases have either completely disappeared or become much more muted.

This output is exactly what we would expect from our Reactive Model. The model’s recommendations are entirely driven by market behavior, not speculation or historical assumptions.
Part 5: Blending Demand Models
We leverage these two models for each day’s recommendation by dynamically blending the demand models together.
On the chart below, we show stay dates on the x-axis, from today (far left) to 365 days out (far right). On the y-axis, we show the weighting (from 0% to 100%) that our Reactive model has for any future stay date. The reason the curve slopes up (from right to left) is that as a stay date approaches, our Reactive Model starts to have a much bigger impact on that day’s price recommendation.
Additionally, the spikes you see in the line show where a large number of bookings cause our Reactive Model to be more heavily weighted sooner than normal. Said differently, when we see a big demand spike and have high certainty that this is a clear market signal, our model very quickly responds to that demand.

Part 6: Calendar Controls & Response
How Wheelhouse adjusts pricing around bookings & approaching vacancies
There are two key aspects of calendar control that impact revenue:
- Vacancy gaps
- Temporality
Vacancy Gaps
In San Francisco, single night gaps have a probability of only 7.3% of being booked, compared to a normal day in the market, which has a booking probability of 41.1%. As this ‘vacancy gap’ gets larger (i.e. two or three nights) the booking probability for these days increases.

Thus, our pricing engine uses a combination of the vacancy gap length and the day of week to determine an appropriate discount for any vacancy gap that emerges on your calendar.
On a daily basis, our model is reviewing each unit’s calendar, to try to maximize revenue while respecting minimum stay rules and the calendar blocks that customers control.
Last Minute Pricing
For example, let us look at the graph of how operators discount prices over time, as a stay date approaches. As we can see here, about two weeks before the stay date, average booking prices start to drop until they have dropped by almost 30% for same-day bookings.
While this varies by market and unit, Wheelhouse incorporates discounting schedules into our price recommendations as a ‘temporality adjustment’, which dynamically reduces the price as the stay date approaches.

Part 7: Competitive Set Modeling
In the STR space, automatically detecting an accurate competitive set can be quite challenging. This is due to the highly variable supply of the STR space, that sometimes creates non-intuitive competitive sets.
For example, it is not unusual to have a 1 BR unit that can sleep 4 (or even more!) guests. Due to this, it would not be unusual to find that an ‘accurate’ competitive set for this unit would include 1BR, 2BR, or even 3BR units.
Additionally complicating matters is the fact that many ‘similar’ nearby units may not actually be true competitors. (Said differently, not all 1BR places are the same!) This can be due to neighborhood boundaries, differing amenities, reviews, or more. For example, if your unit has a pool, your competitive set should likely include (at least in the summertime!) nearby units that also have pools.
Given this complexity, we have found that the most effective Competitive Set can be determined by determining which units have the most similar combination of features.
In this manner, we have an expected base price, as well as an expected occupancy, for each unit in a market. However, this approach abstracts from the unit features to a more generic comparison that implicitly values similarities in e.g. amenities, bedrooms and location based on how they perform in the market.
Utilizing the differences in base price, expected occupancy, and geographic distance, we then perform a cluster analysis to identify the final recommended competitive set.
In this case, our Comp Set model identifies a competitive set of 90 units. Among this competitive set, 68 units are also zero bedrooms, while the other 32 have one bedroom. And, while 74 of the units are also classified as ‘private rooms’, 16 of the units are entire homes/apartments.
The results are shown in the following visual, which depicts each nearby unit as a singular dot.
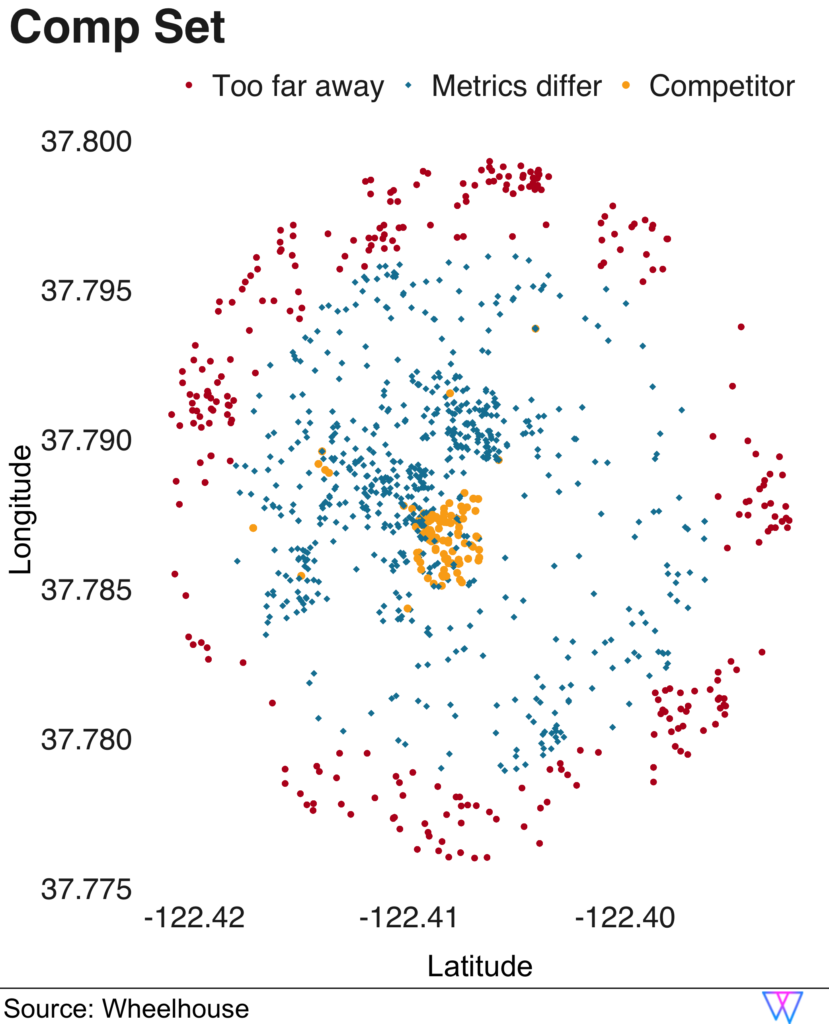
For the next set of more proximal units, our model removes units for which the base price and the expected occupancy do not align (these units are the ‘blue squares’). However, when both distance and similarity are a ‘match’, our model includes this unit in a default ‘competitive set’ (yellow circles, clustered at the center).
Pretty cool! But… ready to dive in even deeper?
Let us further our comp set analysis by examining the distribution of two key metrics, base price and occupancy, for the identified competitors. As we can see on the first chart, our Base Price graph shows where, amongst a comp set, this unit’s Base Price falls. In the second chart, we can see that the distribution around occupancy is actually considerably broader, though still similar, to our sample unit.


The third chart below offers one more vantage point to see how our Comp Set model works.
In short, when we examine the distance metric, you can see that while our competitive set model clearly favors units that are close by. But, it also considers some units farther away, if they show very similar performance metrics.

In total, Wheelhouse’s Comp Set model identifies and compares both a broad and narrow set of competitors. Over the years, our data has illustrated that it is best to price against a larger set of ‘potential competitors’, as opposed to a smaller set of ‘certain competitors’.
Additionally, due to this approach, we can show customers a broader set of ‘potential competitors’, which can be useful in providing a broader range of insights when either (a) comparing performance metrics or (b) deciding on a pricing strategy.
Part 8: Dynamic Pacing Model
To handle increasingly professional portfolios in the STR space, the Wheelhouse Pricing Engine developed the concept of ‘unit types’. Unit types help properties with similar rooms (such as multiple studios, 1BR, 2BR, 2BR/2BA, etc.) to leverage a ‘portfolio’ approach to pricing. Similar to how hotel pricing works, this approach allows us to make pricing decisions based on the performance of a set of units.
In the graph below, we illustrate the risk-reward ratio changes as a set of rooms begins to book. In this scenario, let us analyze a boutique hotel that has 10 units in a particular unit type.
Before the first booking occurs, the risk of a low daily revenue figure is high. Consequently, increasing prices prior to a first booking also increases the risk of the ‘worst case scenario’ — $0 in daily revenue. Alternatively, if 9 of the 10 rooms for a stay date are already booked, the marginal risk of increasing the price for the last unit is much smaller. Therefore, as more of a property books up, the more aggressively we can potentially price the remaining available units

While one of our newer innovations, we are confident that Wheelhouse has developed the only dynamic pacing model in the STR category. We look forward to continuing to refine this, especially with our urban STR partners.
Conclusion
- Understand each unique unit
- Understand each local market or neighborhood
- Maximize revenue outcomes for single units, or portfolios of units
- Maximize revenue in urban, rural and vacation destinations
- Maximize revenue in high density unit clusters, and highly spread out units
- Adapt over time to the unique performance of each unit
However, we recognize that despite all the effort we put into our pricing engine, the true success of Wheelhouse depends on you. No pricing engine is complete without a skilled operator (you!) modifying our recommendations to better capture your unique business goals.
Therefore, while we love improving our model, know that our team continues to invest just as much time and energy into designing a user-friendly interface, that gives you access to a wide degree of customizable settings and strategies. This effort ensures that you always have the final determination for how to price your unique portfolio.




Blog search
Recent posts
-

Wheelhouse Presents: Ratestrology
April 1, 2023 | BY Andrew Kitchell
-

Short-Term Rental Agreement: What to Include & Free Templates
January 17, 2023 | BY Hailey Friedman
-

Hostfully Review: Vacation Rental Management Software [2023]
January 14, 2023 | BY Hailey Friedman
-

Escapia Software Review [2023]
January 6, 2023 | BY Hailey Friedman




